ROOK vs Spike API: Which Wearable Integration Platform Is Right for You?

Choosing a wearable integration platform is a strategic decision. It affects how quickly you can launch, how scalable your product becomes, and how reliable your wearable data infrastructure will be over time.
If you’re evaluating ROOK vs Spike API, you’re likely building a digital health platform, fitness application, InsurTech product, corporate wellness solution, or data-driven health service that depends on wearable connectivity.
Both platforms aim to simplify access to wearable data. However, ROOK stands out for its focus on data standardization, scalability, and its ability to provide robust infrastructure to support long-term digital health products.
This guide breaks down the key factors to consider.
Why wearable integration infrastructure matters
Connecting to wearable devices involves more than API access. It requires:
Managing multiple manufacturer APIs
Handling OAuth flows and token refresh cycles
Normalizing inconsistent metric definitions
Maintaining compatibility with API updates
Supporting longitudinal time-series data
Ensuring cross-device comparability
Without a centralized strategy, engineering teams often spend more time maintaining integrations than building product features.
ROOK solves this problem by providing a platform that centralizes integration with multiple wearable devices into a single API, simplifying data management, and allowing teams to focus on creating innovative products.
ROOK vs Spike API: Core comparison
1. Product philosophy and architecture
ROOK
ROOK is an API-first wearable data platform designed to:
Aggregate data from hundreds of wearable devices
Normalize and standardize health metrics
Deliver structured, analytics-ready data
Support scalable multi-device environments
ROOK focuses on transforming fragmented wearable signals into comparable, usable health data.
Spike API
Spike API provides connectivity to wearable data sources through a unified integration approach.
It typically emphasizes:
Device connectivity
Developer accessibility
Simplified integration endpoints
Depending on the implementation, data normalization and transformation depth may vary.
2. Data normalization and standardization
One of the most important differences between wearable platforms is how data is structured after ingestion.
ROOK
Standardized metric definitions across manufacturers
Unified data schema
Normalized units and time zones
Designed for behavioral scoring and analytics
This approach reduces downstream data transformation and simplifies:
Incentive models
Risk scoring
Health scoring engines
Longitudinal analysis
Spike API
Provides access to device-level data
Normalization depth may depend on use case and internal processing
If your product depends on cross-device comparability, built-in standardization becomes critical.

3. Engineering overhead
When evaluating ROOK vs Spike API, consider:
Who manages manufacturer API updates?
How are breaking changes handled?
Is normalization provided or expected internally?
How unified is the data model?
ROOK is designed to minimize the additional transformation work for product teams. Our platform provides a unified API, which significantly reduces engineering overhead and allows your team to focus on what really matters: building the product.
Spike API may provide connectivity while requiring additional internal structuring depending on requirements.
4. Scalability and multi-device environments
Wearable ecosystems are expanding rapidly. Users:
Switch devices
Use multiple devices simultaneously
Generate increasing volumes of historical data
A wearable platform should support:
Consistent longitudinal tracking
Device-agnostic analytics
Scalable infrastructure
ROOK prioritizes cross-device comparability, allowing companies to scale their products without worrying about integration issues as they grow.
Spike API prioritizes simplified connectivity workflows, but it may not be designed to support scalability for large volumes of wearable data.
5. Ideal use cases
ROOK may be a strong fit if you are building:
Behavior-based reward systems
InsurTech incentive programs
Corporate wellness platforms
Longevity scoring applications
Engagement-driven digital health products
ROOK is the perfect platform for businesses that require structured and standardized data to drive their business models and create data-driven solutions. Our solution is optimized for products that need deep data normalization and analysis.
Spike API may be a fit if you are prioritizing:
Fast device connectivity
Lightweight integration workflows
Developer-first API experimentation
The choice depends on how much data normalization your product requires.
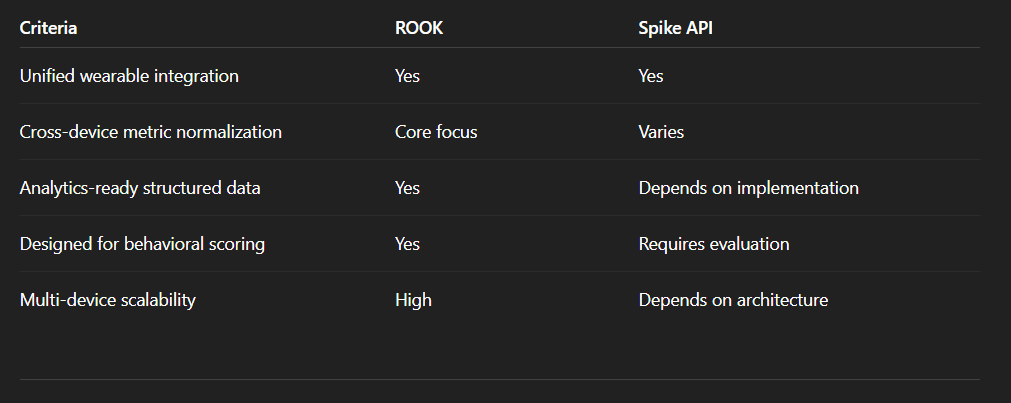
ROOK vs Spike API comparison table
Questions to ask before deciding
Do we need cross-device metric comparability?
Will we build scoring or incentive systems?
Do we have engineering bandwidth for data normalization?
How important is longitudinal consistency?
Are we optimizing for speed of connection or depth of structure?
Your answers will clarify which platform aligns with your roadmap.
Strategic considerations
The difference between wearable connectivity and wearable infrastructure is significant.
Connectivity allows you to access data.
Infrastructure allows you to scale it, compare it, analyze it, and build product logic on top of it.
If your product relies heavily on:
Engagement loops
Incentive structures
Insurance underwriting models
Health scoring systems
Deep normalization and structured data become strategic assets. ROOK provides the infrastructure you need to scale your product efficiently and effectively.
If your product is in early experimentation or prioritizes lightweight connectivity, different trade-offs may apply.
Final thoughts: ROOK or Spike API?
Both platforms offer wearable data connectivity.
The key difference lies in:
Standardization depth
Architecture philosophy
Scalability design
Product orientation
ROOK is designed to facilitate the integration and scalability of products based on wearable data. Choosing the right wearable integration platform should align with your long-term product strategy, not just your immediate technical needs.
As wearable ecosystems grow, platforms like ROOK, which transform data into structured, comparable infrastructure, will be better positioned to support scalable digital health products.
Ready to take your wearable data integration to the next level?
Schedule a call with us today to learn how ROOK can help simplify integrations and accelerate your product development. Here