Understanding Our API: Biomarker Data Structure Vol. 1

When building with wearable data, the challenge is rarely “getting the data.” The real complexity lies in making it usable. Each manufacturer exposes different metrics, naming conventions, proprietary models, and data formats. That typically forces teams to invest significant time in integration, normalization, and long-term maintenance.
At ROOK, we remove that complexity by delivering a consistent structure: we organize data into three pillars, deliver it as summary or event data, and version documents to ensure you always work with the most up-to-date information.
Prefer watching instead? Here’s the full walkthrough on YouTube:
Watch the video on YouTube
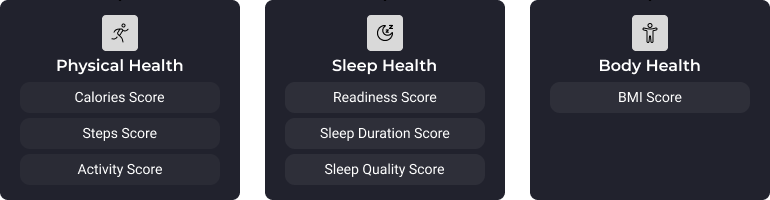
The three core data pillars in ROOK
ROOK organizes wearable health data into three main pillars:
Physical: activity, heart rate, stress, oxygenation, and related metrics
Sleep: duration, sleep stages, nighttime HRV, temperature, and recovery signals
Body: body composition, glucose, blood pressure, nutrition, temperature, and other logged measurements
This structure makes product design clearer: activity dashboards live in physical, recovery insights in sleep, and physiological or lifestyle measurements in body.
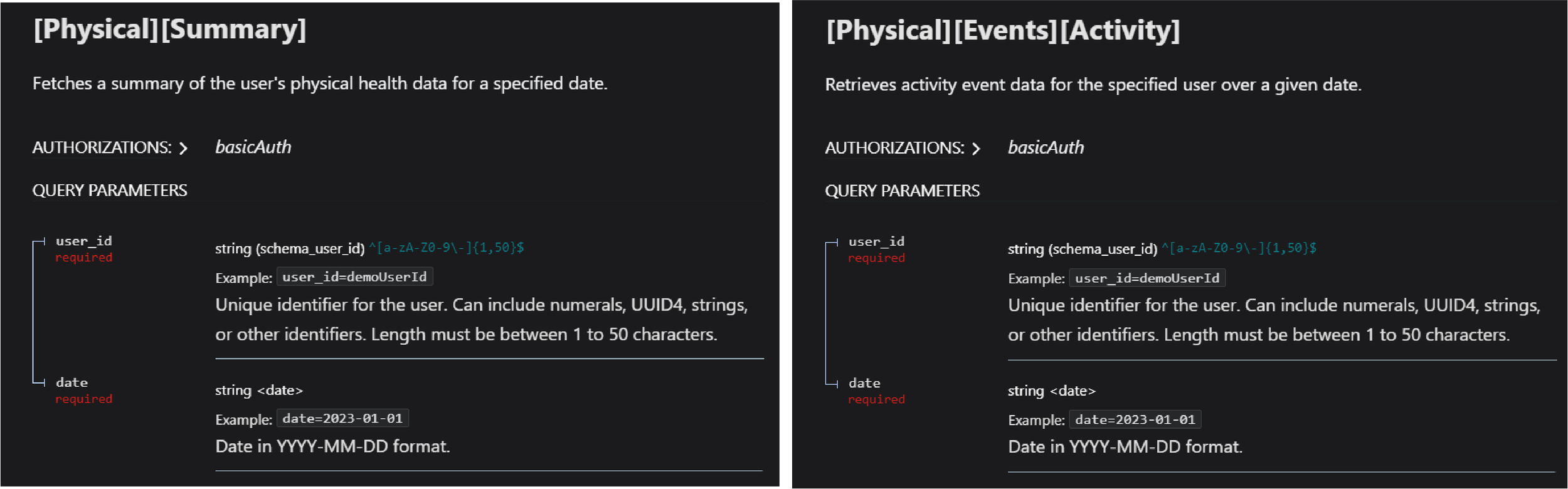
Summary vs. event: the distinction that shapes your product
Within each pillar, data can be delivered in two formats. Understanding them simplifies your architecture and improves product decisions.
Summary data
A summary represents the completion of a time period. It is delivered once sufficient data is available to consolidate results. For example:
Physical summary: end-of-day totals and averages (steps, calories, distance, active time, etc.)
Sleep summary: end-of-night consolidated sleep metrics
Body summary: daily consolidated body measurements
Why summary data is typically your “final” data:
Includes totals, averages, minimums, and maximums
May reflect corrections or late updates from the source
Consolidates multiple connected devices into a harmonized dataset
Event data
Events are triggered when something happens during the day with a defined start/stop or a specific measurement.
Examples:
A workout session
A smart scale weigh-in
Continuous glucose monitor readings
Heart rate or oxygenation triggers
Event data is ideal for:
Real-time dashboard updates
Triggering alerts or interventions
Providing intra-day feedback
Best practice: use events for real-time interaction and summary data for end-of-day accuracy.
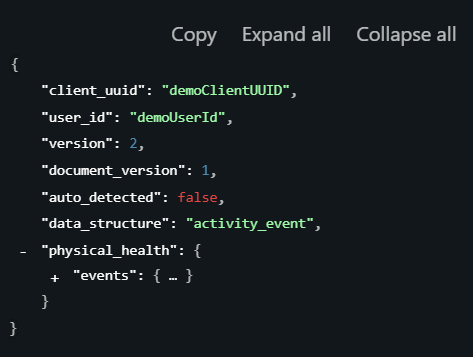
Understanding the JSON structure
Although the content varies by pillar, the structural framework of each JSON remains consistent. There are four key fields you should understand immediately:
Client UUID
Identifies your organization. Generated in the ROOK portal when setting up your account.
User ID
Identifies the end user within your system. You define it, and ROOK uses it to associate all wearable data with that user.
API version
Indicates the API version (for example, v2). Primarily relevant for technical reference and backward compatibility.
Document version
This field is critical for maintaining data integrity.
Document version: how to avoid outdated data
Wearable providers may send an initial dataset and later send an updated or corrected version for the same user and day. That is why ROOK includes document version.
Golden rule:
If you receive multiple records for the same user ID + date + data structure, always use the record with the highest document version.
This ensures:
You are working with the most recent data
Your reporting remains consistent
Late corrections from providers do not create discrepancies
Structured vs. non-structured data
Within each JSON, ROOK separates two types of information.
Structured data
These are metrics that can be standardized across devices, such as:
Steps, calories, distance
Heart rate, HRV
Sleep duration and stages
Stress and oxygenation
Structured data is ideal for:
Cross-device comparisons
Consistent product features
Avoiding device-specific logic
Non-structured data
These are proprietary metrics unique to specific manufacturers, such as brand-specific readiness scores or device-exclusive indicators.
Important: ROOK does not discard proprietary metrics. They are delivered separately so you can use them if relevant, without breaking normalization across devices.
Recommended implementation approach
A robust implementation typically follows this pattern:
During the day:
Consume event data for real-time updates
Use events to trigger alerts, notifications, or UI updates
At the end of the day:
Replace accumulated values with summary data
Always use the highest document version
This approach maintains:
Real-time responsiveness
End-of-day accuracy
Long-term data consistency
Watch the full technical walkthrough
If you would like to see a live walkthrough of the API reference and example JSON structures for physical, sleep, and body data, watch the full video here: